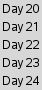
Notice that the name of the label is created using the winNum
variable. This creates labels named .l_1,
.l_2, etc.
Every widget must have a unique name. Sometimes you know just what widgets you'll be creating while you are writing the program:
- A button to set options (named .option)
- A button to get help (named .help)
- A button to exit (named .exit)
Sometimes you don't know what widgets will be created when you are writing the program, the program learns this as it's running. That's what happens in this code - it creates a label for each day when there are events to report and you don't know what days those will be when you are writing the application.
Creating a widget name based on some related value is a useful technique for creating widget names on the fly when you don't know what windows you'll need when you are writing the application.
Also notice that the grid command is using a variable to hold the row and adding one to this variable on each pass through the loop. Using a variable instead of hardcoding the row numbers makes a program more adaptable, since it can grow or shrink as required.
set row 1
set column 1
set winNum 1
foreach day {20 21 22 23 24} {
label .l_$winNum -text "Day $day"
grid .l_$winNum -row $row -column $column
set row [expr {$row + 1}]
set winNum [expr {$winNum + 1}]
}
The grid command will expand or shrink any field to fit the widgets you
place in it. Try changing the grid command to use the $day
variable instead of the $row variable.
Does this change the display? Why/Why not?
The first fields in the message.1 file used in this lab follows this
format
- Month
- Day
- Time (hh:mm:ss)
- System Name
- applicationName (with optional [pid]):
- free form message
Because the format is fixed, we can extract specific information (like the
date, time or application) using the cut command.
This code returns a list of all the type fields:
set types [exec cut -d " " -f 5 /Volumes/Scratch/messages.1 ]
puts $types
These values include the pid value. If we invoke cut again, we can
use a [ as the field delimiter and get just the name:
set types [exec cut -d " " -f 5 messages.1 | cut -d [ -f 1]
puts $types
Put that command into a file and test it. You'll receive an error message like this:
missing close-bracket
while executing
"set types [exec cut -d " " -f 5 messages.1 | cut -d [ -f 1]
The square bracket is just another character for the cut
command, but it has meaning to the Tcl interpreter. In order to pass the
square bracket to the cut command, it needs to be protected from the Tcl
interpreter. This can be done with a back-slach (\\) or with curly braces.
set types [exec cut -d " " -f 5 messages.1 | cut -d {[} -f 1]
puts $types
The variable types now has an entry for each line in the file. We can reduce
that to just the distinct types of messages with the sort command:
set types [exec cut -d " " -f 5 messages.1 | cut -d {[} -f 1 | sort -u]
puts $types
Write a script that uses this command to display a label with a list
of the distinct types of messages in the messages.1 file.
Use a separate label for each message and place each label on a separate line.
Add a button to exit the application to the previous example.
The result should look like this:

Use two loops to create a 2-D display that looks like this:
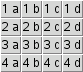
One loop will step through a list of letters and the other will step through a list of numbers.
When you enter it and run it. You'll see a result like this:
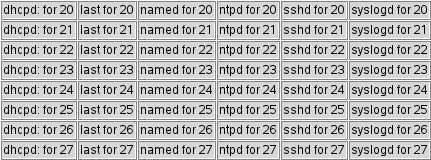
# The variable winNum is used to provide a unique name
# for each window.
set winNum 0
# Loop on days that we know exist in this log file.
# Real code might do a pre-scan to find out what days are actually present.
foreach day {20 21 22 23 24 25 26 27} {
# Column must be initialized inside this loop
set column 1
# Create a label for the day and grid it
# Note that the $day variable is used for the row
# The grid command ignores empty rows and columns, so this leaves
# no blank spaces.
label .day_$winNum -text $day
grid .day_$winNum -row $day -column $column
# create a new winNum for the next window
set winNum [expr $winNum + 1]
# Loop for the messages we know are in this file
foreach type { dhcpd: last named ntpd sshd syslogd } {
# A new label : note the -borderwidth and -relief options
# these make the labels obviously separate
label .type_$winNum -text "$type for $day" -borderwidth 2 -relief ridge
grid .type_$winNum -row $day -column $column
# Create new winNum and Step to next column
set winNum [expr $winNum + 1]
set column [expr {$column + 1}]
}
}
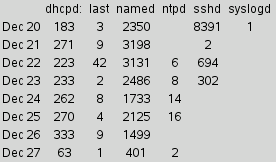
Look at the code and the image closely. There is code to create labels with just the date, but they don't appear in the image. The first "type for $day" label overlays the day label.
This is caused by a common type of programming error that occurs when calculating a new location inside a set of loops.
This can be fixed by moving one line of code. Fix it so that the display looks like this:

exec command will return the results of the system commands it runs.
Whatever would be displayed on stdout is returned by the exec command.
The exec command can use pipes the same way that a shell script can.
This means you can write small applications like this:
set count [exec grep sshd messages.1 | wc -l]
tk_messageBox -type ok -message "There are $count sshd messages in messages.1"
exit
Type in that code and test it.
Modify the code above to show only the ssh
messages with invalid in the message.
exec command passes the status return up to the
Tcl interpreter. For instance, if grep cannot access a file,
the exec command will throw an error.
Put this line into a file and execute it to see the result:
exec grep foo /var/db/BootCache.playlist
The grep command also returns a failure if it fails to
find any matches to a string.
Put this line into a file and execute it to see the result:
exec grep NoSuchLine messages.1
This presents a problem when using a Tcl script to exec grep commands. For example looking for multiple patterns in a file will abort the application if the pattern is not present.
There are several solutions to this problem.
One solution is to preselect only patterns that exist in the file.
You might think that you could look for sshd attacks on separate days with the code below.
set row 1
foreach day {20 21 22 23 24 25} {
set ssh_count [exec grep sshd messages.1 | grep password | grep "Dec $day" | wc -l]
label .l_$day -text "Number of SSH messages on Dec $day is $ssh_count"
grid .l_$day -row $row -column 1
set row [expr {$row + 1}]
}
Try typing in this code to see what happens. (Or you might just guess that it will fail because there are some days when there was no attack.)
We can select the days when an attack occurred by grepping for the attack patterns, selecting only the day from the result, and then sorting to get only the unique values.
set days [exec grep sshd messages.1 | grep password | cut -d " " -f 2 | sort -u]
Rework the example above to figure out which days should be tested and then display the days.
Don't be surprised that this application will take quite a while to run. It has
to run the grep command several times.
The results should resemble this:
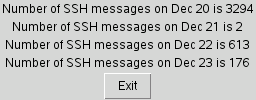
The results should look like this:
Elapsed Time = Loop Count * Time to process
Nested loops take even longer, since you go through the outer and inner (and perhaps more inner loops) multiple times. For two loops, you can calculate the time like this:
Elapsed Time = OuterLoop Count * InnerLoop Count * Time to process
Two ways to speed up processing are to reduce the number times your code iterates through the loops and to reduce the processing time.
You can reduce the time it takes grep to process a file by making the file smaller.
You can reduce the size of the file being grepped by creating an intermediate file with code something like this.
exec grep ssh messages.1 >tmpFile
Modify the previous code to create intermediate files and
grep for the various types of messages on the days that
the messages are available.
The loops can be left in their current order and grep can
be used to extract the messages for a given day, or the loops can be
rearranged to put the message types in the outside loop and the days on
the inner loop. In either case, your code will need to find the values
that actually exist in the file before starting a loop.